
The key challenge for machine learning parameterizations of clouds
The argument goes like this: Climate models continue to have large uncertainties → these uncertainties are primarily caused by the parameterization of sub-grid clouds which are based on heuristic assumptions → short-term high-resolution simulations are now possible→ so why not learn a parameterization directly from high-resolution data?
Motivated by this line of thinking, a growing number of researchers are embarking on the quest to build machine learning (ML) parameterizations of sub-grid processes. This started with the paper by Vladimir Krasnopolsky in 2013 and in 2018 saw a big uptake in interest with papers published almost simultaneously by three research groups (Rasp et al., Brenowitz and Bretherton and O’Gorman and Dwyer). Since then research efforts have only intensified. And initial studies do indeed show the feasibility of this approach. The three groups mentioned above have all managed to run a hybrid climate model with ML cloud physics that reproduces some key features of the high-resolution simulation.
Reality check
However, it is important to put into perspective what has actually been achieved so far. As of yet, all of the simulations have been run in a very simplified setup, namely an aquaplanet, and while some of the high-resolution features were reproduced, we are a long way from actually creating a better climate simulation. What’s more, getting these simulations to run is not trivial and they are still plagued by nagging issues. In our own work, for example, instabilities were a big problem, where the neural network, once plugged into the climate model, would sometimes create runaway feedbacks that would crash the model. We now understand a little better why this is happening but not enough to have a principled solution. As another example, in the study of Noah Brenowitz and Chris Bretherton the long-term simulations drifted further and further away from the reference climate, likely due to the difficult process of coarse-graining. Generally, estimating the sub-grid tendencies from high-resolution simulations is not a trivial process.
The optimization dichotomy
While all of these issues can likely be fixed in some way, I think there is a much bigger issue to be overcome if ML parameterizations are ever to lead to actually better climate forecasts. Let me call that issue the optimization dichotomy. The basic version goes like this: When optimizing ML parameterizations, one trains the ML model to predict the instantaneous tendencies caused by the sub-grid processes given a large-scale state at a column. However, what we really want in the end is better climate statistics (e.g. TOA radiation balance) or a better weather forecast several days ahead. However, this means that there is a huge gap between what we optimize for and what we actually want in the end. What lies in-between are thousands to millions of time steps in which a multitude of model components (ML and physical) and grid points interact in very non-linear ways. This means that even if we manage to train a stable, conservative ML parameterization that very accurately reproduces the instantaneous tendencies of the high-resolution model, this is no guarantee that this will actually lead to better climate or weather forecasts. To compound this issue, the best such a parameterization could do is to reproduce the high-resolution simulation which also have short-comings compared to observations.
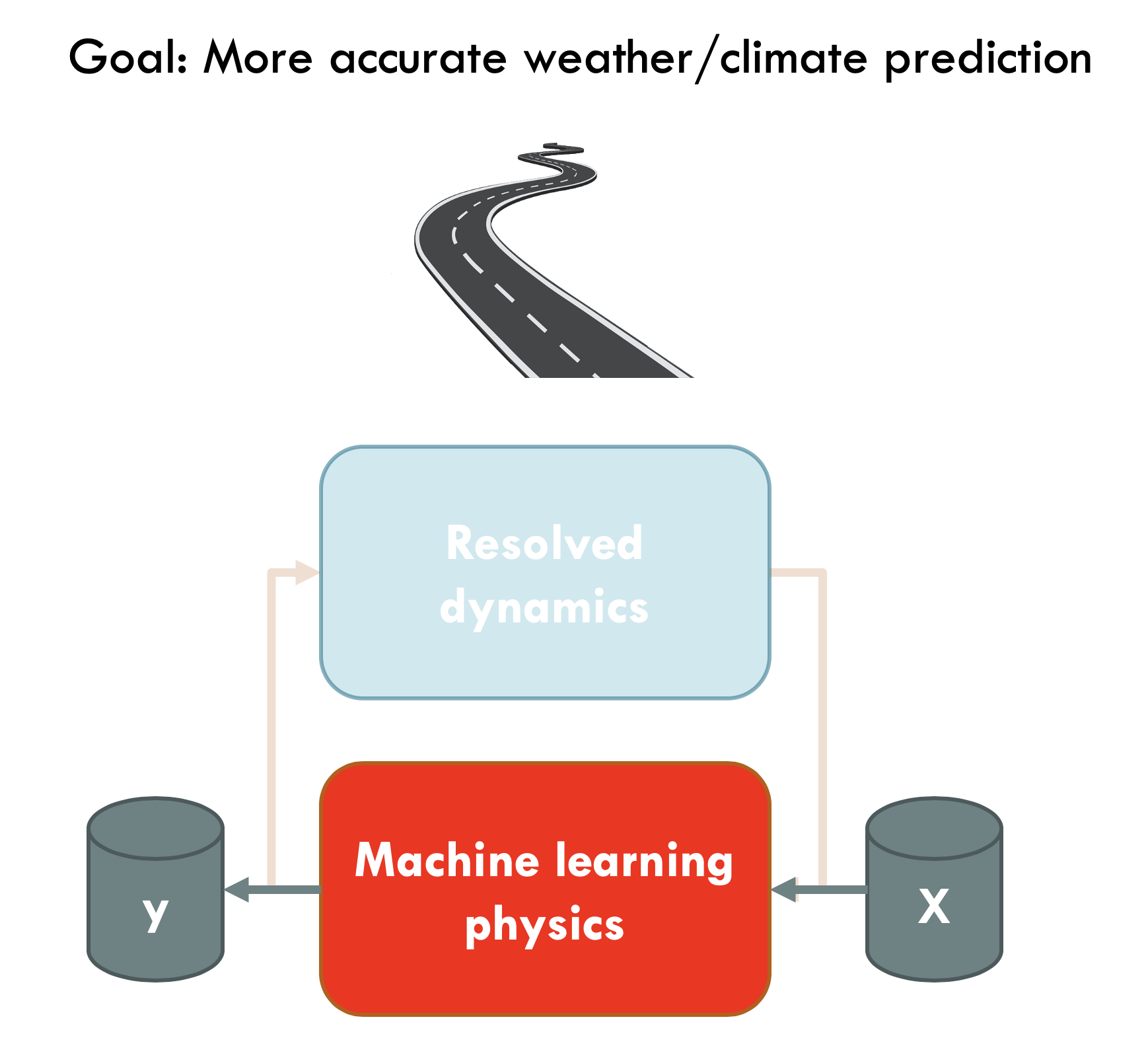 What we are optimizing for is a long way from what we actually want.
What we are optimizing for is a long way from what we actually want.
In contrast, traditional heuristic parameterizations have a handful of tuning parameters that are manually tuned to achieve the best skill based on years of experience and physical intuition. This is certainly not an ideal process since all the Terabytes of data have to go through a human bottleneck but it does allow for some tuning. But what if my ML parameterization has a positive precipitation bias in the tropics, to name just one potential example? Manual tuning is not an option any more because neural networks or random forests have many thousands of meaningless parameters. In the current pipeline of training ML parameterizations there is no way of rectifying such errors unless we revert back to tuning the “meaningful” parameters inside of the remaining physical parameterizations.
One hope is that, if the ML parameterization is good enough, it will end up producing better predictions even without tuning. This may or may not be true but to me this seems rather unsatisfying. Further, evidence from the existing coupled studies certainly suggests that unexpected errors or drifts do certainly pop up.
I should also mention that these comments are mainly targeted at the parameterization of sub-grid cloud processes and also turbulence based on high-resolution simulations. This area is particularly difficult because the problem is not well defined and requires a coarse-graining step. If a good parameterization exists but is just too expensive, emulating this parameterization with an ML model might be more feasible if the generated training data sufficiently covers the possible parameter space. Bin-Microphysics or line-by-line radiation parameterizations are such examples. However, similar issues as mentioned here might still arise.
Paths forward
So what to do? First, I think it is important to acknowledge this problem and recognize that studied that evaluate ML parameterization in isolation from the rest of the model. Given enough training data neural networks or random forests will be able to emulate practically any process (with a potential loss of variability) but the real value of a learned ML parameterization can only be judged once it is coupled to the rest of the model. From my own experience, I know very well that coupling the ML parameterization to a climate model is exponentially harder but I personally would like to see more of a push in this direction. Luckily, tools are becoming available to make coupled testing much easier.
Second, we have to start exploring solutions to the problem. I would like to highlight two approaches in this direction. The first one has been much talked about of late: differentiable physics. The idea is that rather than optimizing the ML parameterization in isolation, one uses a fully differentiable atmospheric model which allows optimizing the free parameters over many time steps in a fully coupled context. In theory this would also enable us to optimize directly for the desired target, for example climate statistics or weather forecasts. From an intellectual point of view, this approach is very appealing. However, one hurdle is that this would require a fully differentiable climate/weather model. To some extent these already exist. For example, certain weather models, like the operational ECMWF IFS model, have hand-coded adjoint models for use in data assimilation. Maintaining an adjoint, however, is a huge effort which is why they are not available for most models. Another approach would be automatic differentiation but, again, at this time doing so for an operational climate or weather model would be a daunting engineering challenge. Maybe the new Julia model developed by CliMA could be one step in this direction. Another open question is how scalable this approach is. From what I have seen so far, studies in this direction either optimize only a handful of parameters (rather than many thousands as in a neural network) or they look at very small and idealized problems. Scaling these approaches many orders of magnitude to a much more complex system could well push this approach to its limits. The key question is to which extent the gradients do still make sense. Here, I would be very interested to see the next step taken by increasing the complexity of problems studied.
The other approach is non-differentiable optimization, explored by the CliMA project. The idea here is to use a statistical approach to link the parameters to be tuned to the climate statistics in question and optimize directly for those. However, the plan in CliMA is to do this for the around one hundred traditional tuning parameters of the model. It is rather questionable whether this approach would work for a deep neural network because creating each training sample requires a full GCM run. In theory, using the gradients in the differentiable physics approach should give you more information and therefore more efficient optimization but how this works out in reality for a problem of this complexity is so far unclear.
Either way, one take-away message is that ML parameterizations should always be considered in the context of the model that they will end up in. Similar approaches and training data can probably be considered for many models, and transfer learning might be a real opportunity, but the final optimization has to be done for each model separately. This is not unlike traditional parameterizations which require manual parameter tuning for each model as well.
One problem among many
The optimization dichotomy is what I believe the most fundamental obstacle on the way to improving climate and weather simulations. However, it certainly isn’t the only one. For climate simulations another often talked about issue is extrapolation to unseen climates. To what extent this is an issue depends very much on the training data. If high-resolution simulations are the ground truth, it might be feasible to run these simulations for all climate states of interest. Extrapolation might be hard for neural networks but they are decent at interpolating between training samples. If observations or reanalyses are taken for training - which is probably desirable- then extrapolation is a real problem and will require clever solutions, such as the climate-invariant parameterizations developed by Tom Beucler and colleagues. For long-term optimization as in the two approaches mentioned above, another difficult challenge will be how to engineer the loss function. How does one assign a scalar to a “good weather/climate forecast” when there are so many variables and time-scales to consider. Overfitting to the chosen metrics will likely be a real concern.
Before wrapping up, I should highlight that what I wrote here applies only to the narrow focus of actually improving state-of-the-art weather/climate simulations within the next 5-10 years. There is a lot of valuable research to be done that doesn’t directly pursue this goal and examples of that abound in the literature. In summary, I think that research in ML parameterizations should continue to explore new directions but also focus more on running coupled simulations in increasingly complex contexts and figuring out how big of a problem the optimization dichotomy is and how to overcome it.
Leave a comment